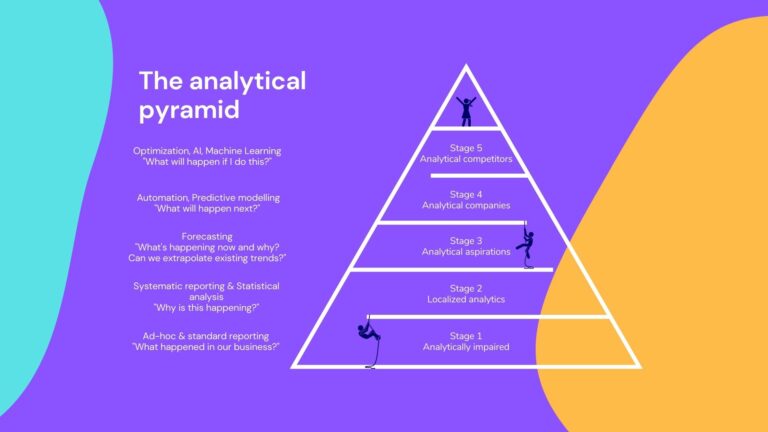
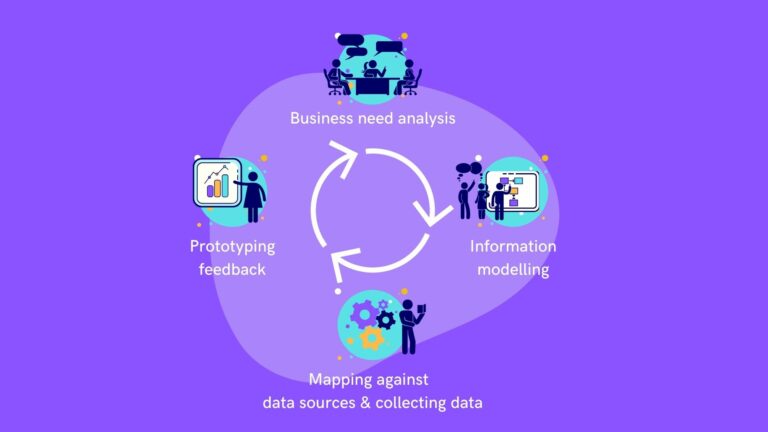
Welcome to our comprehensive blog series on the intricacies of Analytical Data Storage Systems. In this series, we delve deep into the evolution, challenges, and best practices of designing and implementing effective data storage solutions for analytical purposes. From exploring the rich history and fundamental design principles to comparing cutting-edge data modeling techniques, each post in this series offers valuable insights and expert guidance tailored for professionals navigating the complex landscape of data storage. Stay tuned as we unfold the layers of this crucial topic in detail. This is part 1/6 where we’ll focus on the fundamentals and history of “Analytical Data Storage Systems”.
This blog series delves into the principles of designing systems that store data for analytical data products, emphasising the need for maintainability, scalability, and adaptability throughout their life cycle. Building an Analytical Data Storage System presents a unique challenge: its purpose, supporting analytical data products, is defined broadly, without specific, detailed use cases.
In contrast, operational systems (backend/frontend) are built with well-defined use cases in mind, allowing for optimization specific to those scenarios. However, Analytical Data Storage Systems require a different approach, one that caters to potentially unknown data products.
These systems, whether referred to as Data Lakes, Delta Lakes, Data Lakehouses, or Data Warehouses, share common challenges in architecture, design, and implementation, regardless of their names, underlying technology, or whether they are used for streaming, batch processing, or API calls.
So if nothing is defined what are we actually even building? Well, it’s not that bad, there are actually fundamental properties that these systems will have. Bill Inmon, in his seminal work “Building the Data Warehouse,” outlined key properties for these systems:
- Subject-oriented: An analytical system should deliver information about a specific subject of a company’s operation, rather than to just pass along the operational source systems data to reports. I.e. if we have two different order systems (for instance e-commerce and physical store) there should just be one, business representation, of what an order is.
- Integrated: The data in the analytical system should be integrated, even if it’s coming from different operational systems. This has a dual meaning. First of all, regardless of “how” the data is coming, and in what format (e.g. CSV’s, API’s etc.), the analytical system transforms it into a standardized format. Secondly, where possible, the analytical system builds the relationships across the different subject areas so that we it’s “connected”.
- Time-variant: This might be the biggest difference between an analytical system and a classic operational system. The analytical system provides both a current and historical representation of the data. It might sound easy but a lot of the complexity and thus also difficulty arises.
- Non-volatile: This means that data isn’t replaced/destroyed, but rather inserted.
These properties, crucial to the system and data architecture, will be explored in subsequent articles.
Historically, the development of Analytical Data Storage Systems was often an afterthought, not a strategic design decision. Early computing systems focused on business process support and data creation, with little consideration for the architecture or design needed for effective data storage and retrieval. This led to simplistic solutions like copying data to another platform for analysis, without regard for maintainability or scalability.
While operational system design has been extensively researched and evolved, analytical system design has not received the same level of attention. The late 1980s and early 1990s saw pioneers like Barry Devlin, Paul Murphy, and Bill Inmon advocate for specific design approaches to Analytical Data Storage Systems. Yet, the literature often provided high-level blueprints without practical implementation guidance.
Moreover, the rise of profit-driven solutions and technologies often overlooked the core nature of these systems, leading to numerous failed implementations. The advent of Data Lakes in the 2010s exemplified this, with a return to simplistic design principles and a failure to understand the valid principles already in place. This has continued with other platforms, such as DBT and other implementation platform. It is not the platform that ensure good design, its the correct logical design principles applied on a platform that ensure that you build an analytical data storage system that is maintainable, scalable and with good adaptability throughout the systems whole life cycle.
The industry is now seeing a resurgence in interest in fundamental design principles. This series aims to provide insights into not only the ‘what’ but also the ‘why’ and ‘how’ of successfully implementing Analytical Data Storage Systems.
Summary
In this opening article of our series on Analytical Data Storage Systems, we have embarked on a journey through the evolution and fundamental principles of designing such systems. We have highlighted the inherent challenges in building a system that must remain flexible, scalable, and maintainable throughout its lifecycle, particularly when the specific use cases it must support are not always clearly defined.
Our exploration began with the historical context, underscoring how these systems were initially an afterthought in the world of computing, and how they have since evolved into a critical component of data strategy. We touched upon the pioneering work of experts like Bill Inmon and the shift towards recognizing the need for distinct design and implementation strategies for these systems.
Despite the advancements and the recognition of the field, we noted the challenges that have persisted due to a lack of comprehensive academic focus and the distraction of technology-driven solutions that often miss the mark on addressing core design principles.
As we move forward in this series, we aim to delve deeper into the ‘what’, ‘why’, and ‘how’ of designing Analytical Data Storage Systems. We will explore the key properties such systems should support, as outlined by Inmon, and how these principles can be practically applied to build robust, effective systems. Our goal is to provide insights not just into high-level concepts but also into actionable strategies that can prevent the pitfalls of past implementations.
Stay tuned as we continue to unravel the complexities of Analytical Data Storage Systems, providing a clearer path for those looking to build and maintain these systems effectively.